How to Update Complex State Objects in React
I was lead developer for a recent release that involved building a complex React web form. This wasn’t like normal forms, as the single page application consisted of six different forms that would produce six separate database records, but be submitted as a single POST request. Because of the large number of input values I was managing, as well as the segmenting of the forms, I decided to use a complex React state object in my form.
React can handle state in many ways. While the original class based React components stored state in a single state object, functional components introduced the useState hook which allows for smaller, more manageable state objects. With useState you can create multiple state variables within your functional component in order to manage state with primitive values instead of being confined to a single, complex state object.
While this simplicity is nice, there are benefits to using complex state objects. There were two main benefits I found in my application. The first came with ease of rendering as the forms I was building were very similar in their content. Due to this similarity, I was able to structure my complex state object in a way that allowed me to iteratively render DRY form sections. The second benefit came from the ability to populate and manage a ready made object that, after calling JSON.stringify(), allowed me to directly attach my data to my form’s POST request body without any further serialization.
These two benefits proved that I had made the correct design decisions, but when implementing this design I had trouble with creating and updating controlled input components. Controlled input components are a React patten in which we store the input element’s value in state, and every time state changes, we update the user display. This is a very common pattern that I’ve used many times before, but when I implemented it I noticed that the input’s display and the app’s state weren’t updating correctly.
React prides itself on simplifying state management, but this bug didn’t seem to support this key strength of the library. A very simple React pattern was failing, but not due to React. As I dug into this bug I found that to use complex state objects correctly, I needed to fully understand how JavaScript treats copying objects.
How JavaScript Copies Objects
Before we talk about how JavaScript copies values, we first need to discuss how JavaScript stores values in memory. In JavaScript nearly everything is an object with the exception of primitive values (strings, numbers, booleans, symbols, null and undefined). This is important to note as the type of the value determines where JavaScript stores the value in memory, and how we access it.
For JavaScript there are two locations to store data: in the call stack and on heap. The call stack is the memory location where we store and work through the context of a program. If we call a function, we add the function call to the call stack and then add its operations and data to the stack as well. We can view the call stack as an errand list where we may have a command to do our laundry (a main function) and have to work through the different steps of gathering laundry, determining where the laundry mat is (defining variables), traveling to the laundry mat, cleaning clothes and returning before we are able to remove the task from our list (call stack).
As we process the different operations, we will remove them from the call stack one at a time until the function has been fully performed and the main function pointer is removed from the stack. This process follows the LIFO pattern (last in first out) as the most recent operations called by functions are processed before their parent processes are completed and removed.
Because the call stack needs to be quick, we only use it to store values that are statically sized. These are values that, when declared, will not change in how much memory they consume. Primitives work great here as their exact value and size is determined when they are declared or reassigned.
An item like an object, array or function, is variably sized and therefore does not fit the criteria of our small, fast and statically sized call stack. We can see a breakdown of what is stored in stack and heap below:
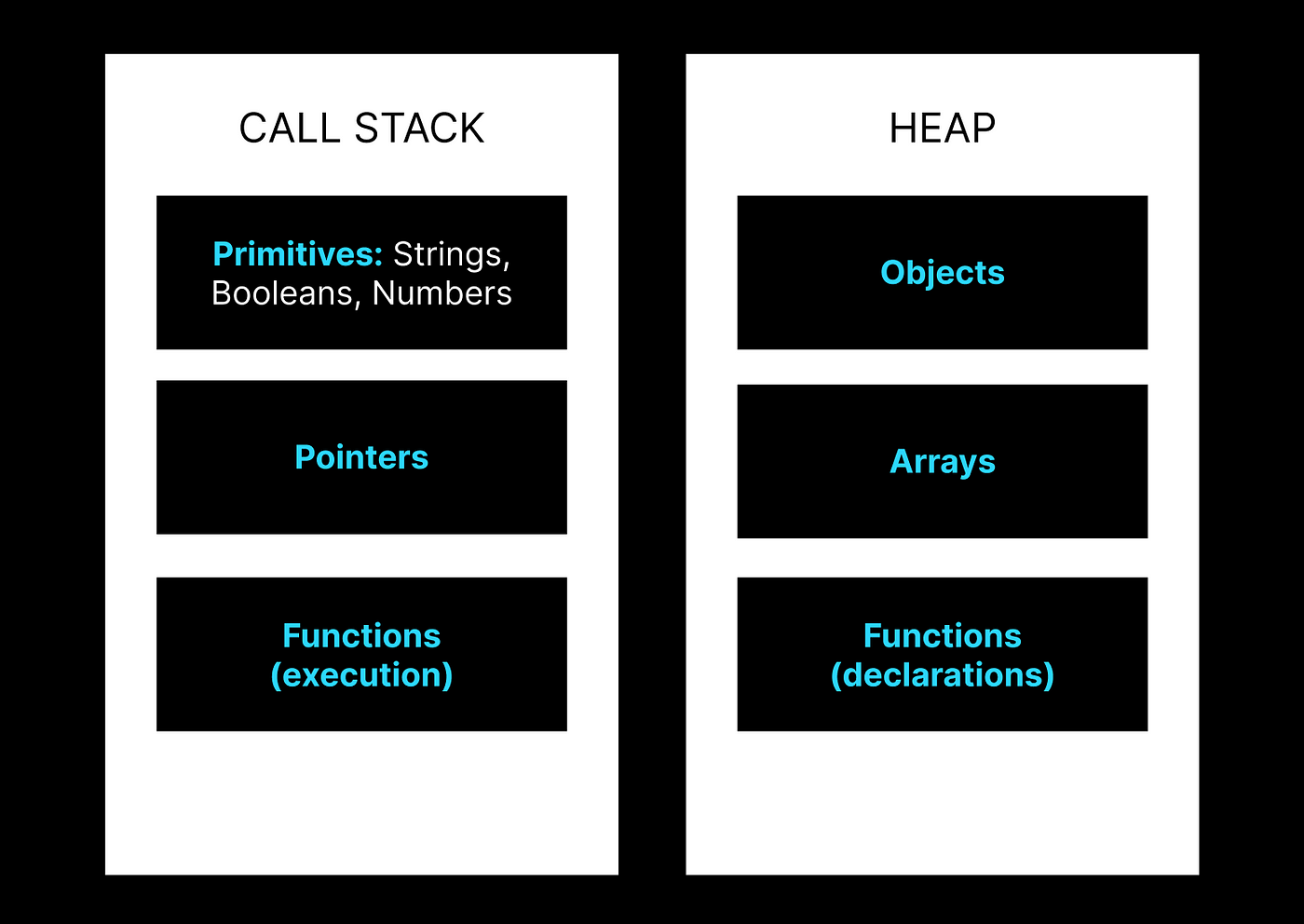
Now that we understand what types of values will be stored in both the call stack and heap, let’s look at how assignments actually work. Let’s first look at one of the most basic assignment and value comparison objects: strings.
With strings, each string we declare is a unique value stored on the call stack. If we define a string “name” with a value of “Daniel” and then create a new string called “name1” and assign it the “name” variable’s value, it will also have a value of “Daniel.”
If we were to look at the call stack, these are two separate variables stored within memory. However, when we do strict equality checks on the values we see that they are equal. If we change the value of the name1 variable to “John” and check equality again we will get false because the two values are not equal:

These outcomes are caused by how strict equality works as it checks equality by both value and reference. Primitive values stored in the call stack don’t have references because they are both defined and stored in the call stack. This allows for a true comparison as their values are equal even if they are independent variable instances. Objects do have references and this is where the complexity of JavaScript memory comes in.
Because we can’t store variable sized values like objects, functions and arrays in the call stack, we have to store them in the heap. The heap is an unstructured grouping of memory, so without a map to consult it would be impossible to find our values. Luckily, when we want to perform an operation with an object from the call stack, we can use its defined pointer to find and access the data.
Let’s say we have a variable skuList that’s an array with 3 elements: 1, 2 and 3. We want to make a copy of the skuList for some operation we are performing in our call stack and call it skuListCopy. After defining skuList and skuListCopy, our call stack and heap might look like this:
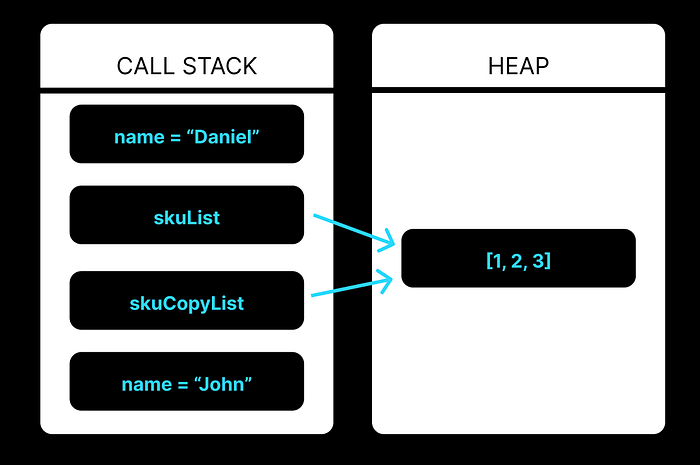
As we can see we have four values in the call stack, our two name values as well as two pointers. The name values are stored solely in the call stack as they are primitives of static size, but there is only one skuList array in heap compared to two references in the call stack. Why is this?
To understand copying we need to understand the difference between copy by value and copy by reference. When we copy a variable by value, as we did with the name variables, we create a new variable instance and assign it that value. At this point the new variable does not point to the old variable and any changes will only affect itself.
The objects, arrays and functions use copy by reference by default. When we create a new object by assigning it the value of an existing object, we aren’t creating a standalone new object. Instead we are creating a new pointer that references our original object. Because of this, we don’t add a new instance of the object to the heap, rather we add a pointer to the call stack that references the existing object in heap memory.
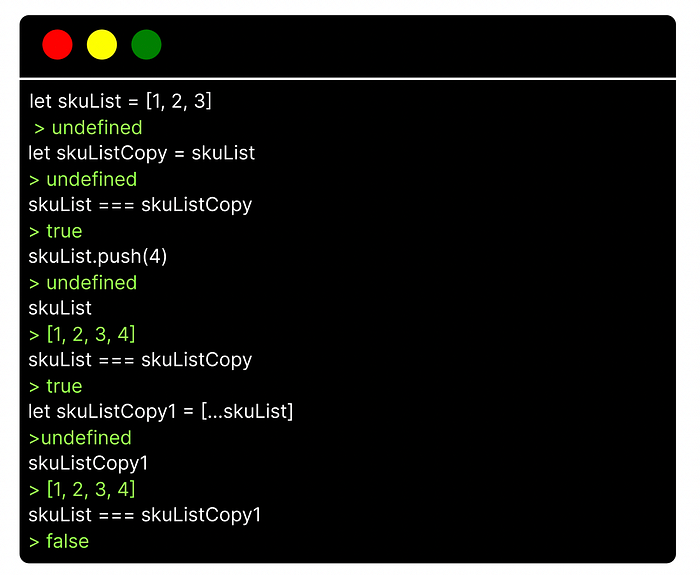
If we update skuList by adding in another sku element, we will indirectly update skuListCopy as it references the same updated object in heap. If we check equality after the update then the values should still be equal.
This is a problem with a library like React as the strict equality check performed on state objects to determine the need for rerendering would return an incorrect false if we operated on a reference copy of the state. The old state would still equal the new state even if we only act on the new state. To get around this we need to create a new instance of the object in heap memory.
My usual choice for creating these new objects is to use the spread operator, but there are many ways to create new objects in heap. By using the spread operator we are able to create a new pointer in the call stack that will now point to a new object in heap that has all the existing object’s data. If we look at the strict equality check between our two objects we see that they are now not equal:
This last point of creating separate object instances in heap ended up being my issue with the complex React state. In the next section we will create a simple React example to look at how the JavaScript call stack and heap memory structures work with React apps.
How React Updates State
Now that we understand the differences between data stored in the stack and heap, as well as pointers, let’s discuss how this intersects with React rerenders. A key part of React is that a component will rerender every time its state is updated. This can have literal cascading effects as state updates in parent components can cause all child components to rerender and lose their state.
We don’t care too much about that now, instead we would like to look at how React knows if its state has been updated. In React there are certain variables and functions that we can use to differentiate regular variable assignments from state variable assignments. For classic class components we access the reserved “state” object that can either be assigned in the class component’s constructor or as a class property.
Functional components offer us more flexibility for declaring our state variables and objects. For functional components we use the “useState” hook to declare a state variable. This state variable can have any name you want it to have. This is great for flexibility, but can make your code more ambiguous.
In order to keep track of state updates, we have to use either setState for class based components, or a custom “set<StateObjectName>” function for functional components. Both of these functions take a single argument, the variable representing the most updated version of state. By only updating the variables with these expected methods, React knows when it should be expecting state changes and rerenders.
You can technically update state by directly modifying the state object, but this can lead to out of sync state and UI presentation issues. We take a functional approach with React state because avoiding direct mutation makes our code more predictable.
This pattern for state management is referred to as unidirectional data flow and is an important part of how React functions. As we can see in the figure below, by having a single state object with a single setter function, we’ve created a simple state machine. Though the actual input may vary for our state object, this unidirectional data flow will always accept input to a specific setter function, update state and cause rerenders in a predictable and repeatable way:
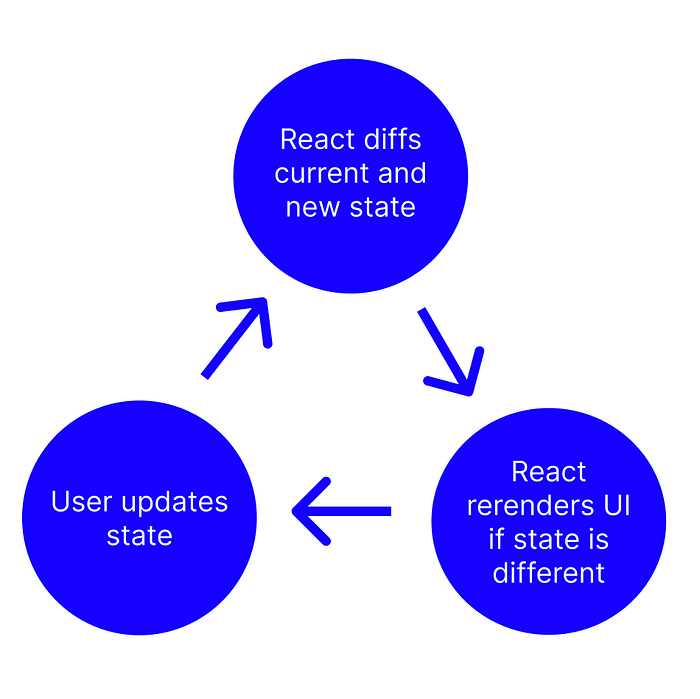
Even if we use the setState or our custom “set<StateObjectName>” functions, we may not see rerenders when we attempt to update state. This is where my bug came up, and where understanding how JavaScript copies objects and pointers comes into the picture.
Because the idea of state updates is based off functional programming, we should never directly modify the state object to force updates. This is simple for primitive state variables, where if we have a state value that represents a name, we can pass a new name string to our setState or set<StateObjectName> methods and always cause a rerender. This gets more complicated when we talk about objects or arrays.
Again, we would like to have a functional approach to how we change our state. To do this we need to create a new copy of our state object to work on and update instead of directly modifying the existing state. We can look at a simple sku management component to better understand this.
Say we have a state object that is a list of available skus to display to the user and we would like to be able to manually add more skus to our list. The code for this would look like this:
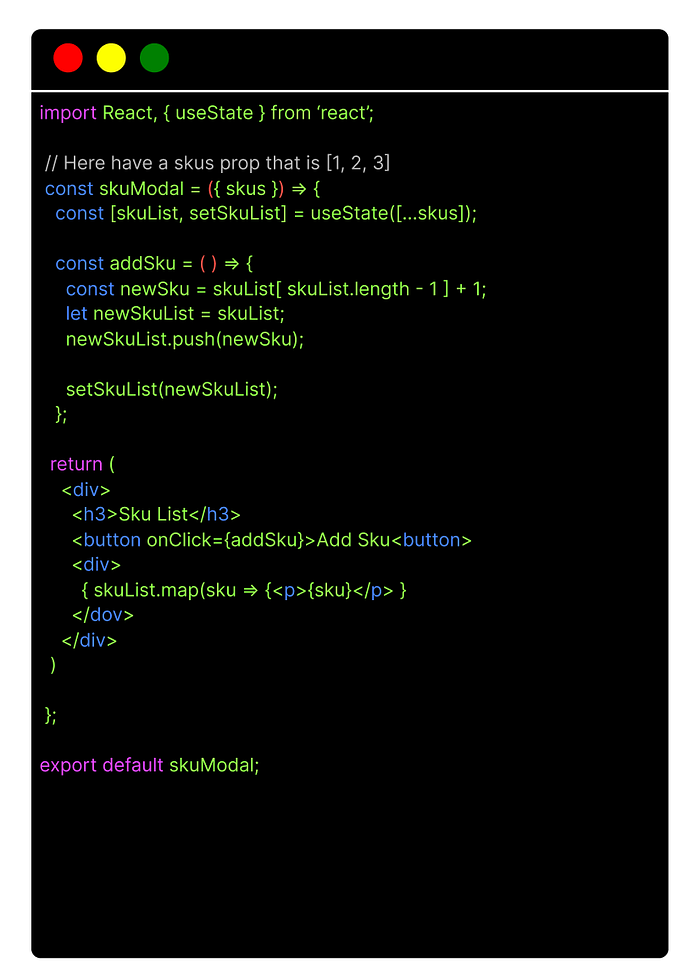
Here it looks like we are adhering to functional principals, but we are actually creating a new copy of the state object by reference. As we’ve established, copying by reference is not a functional approach as any changes performed on the reference copy will update our existing state object directly.
We can console.log() the value of the newSkuList array after we perform a push, but it will show that we have successfully updated the state. However when we go to check the UI we will not see any changes as the old state and new state have the same values and point to the same data on heap.
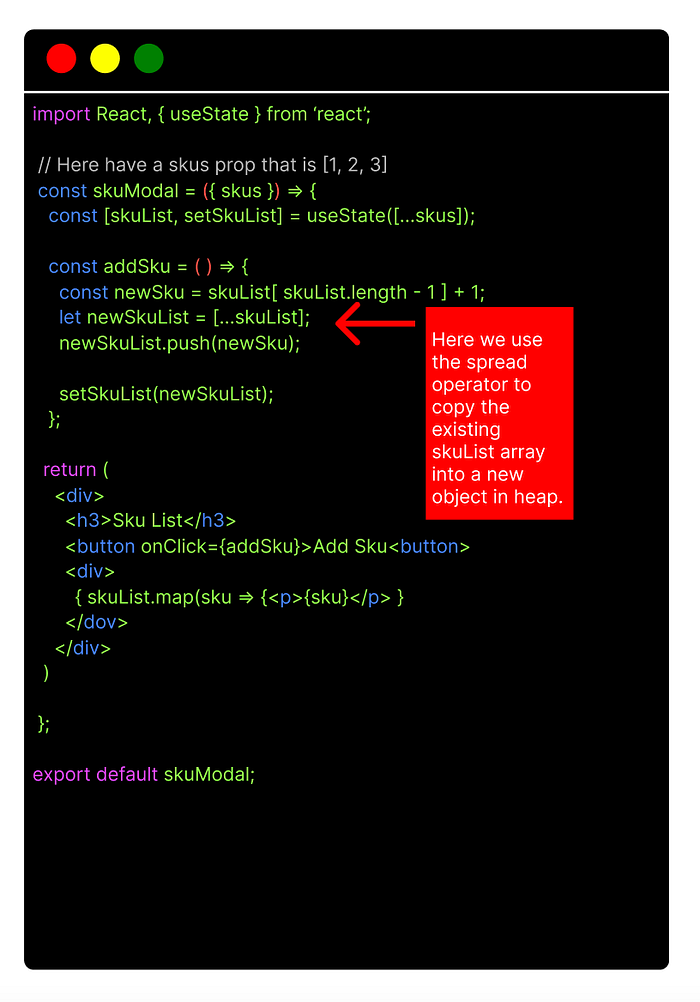
In order to do this correctly we would need to use the spread operator to copy our original state into a new object to modify. This way we are not referencing the original state object and when we go to set state with our new object, React will be able to differentiate between the two and correctly update state and render the changes to the UI:
Conclusion
React makes front end development faster, but also makes it simpler to know how to do something without knowing why it works. I hope that this deeper dive into object references, the call stack and heap and finally how they apply to React state rerenders and UI updates helps you better understand React. There are always more frustrating programming moments, but hopefully out of sync UI updates caused by state references aren’t one of them now.
Notes
https://www.javascripttutorial.net/javascript-primitive-vs-reference-values/
https://stackoverflow.com/questions/37755997/why-cant-i-directly-modify-a-components-state-really
https://www.javascripttutorial.net/object/3-ways-to-copy-objects-in-javascript/
https://blog.logrocket.com/copy-objects-in-javascript-complete-guide/
